Abstract
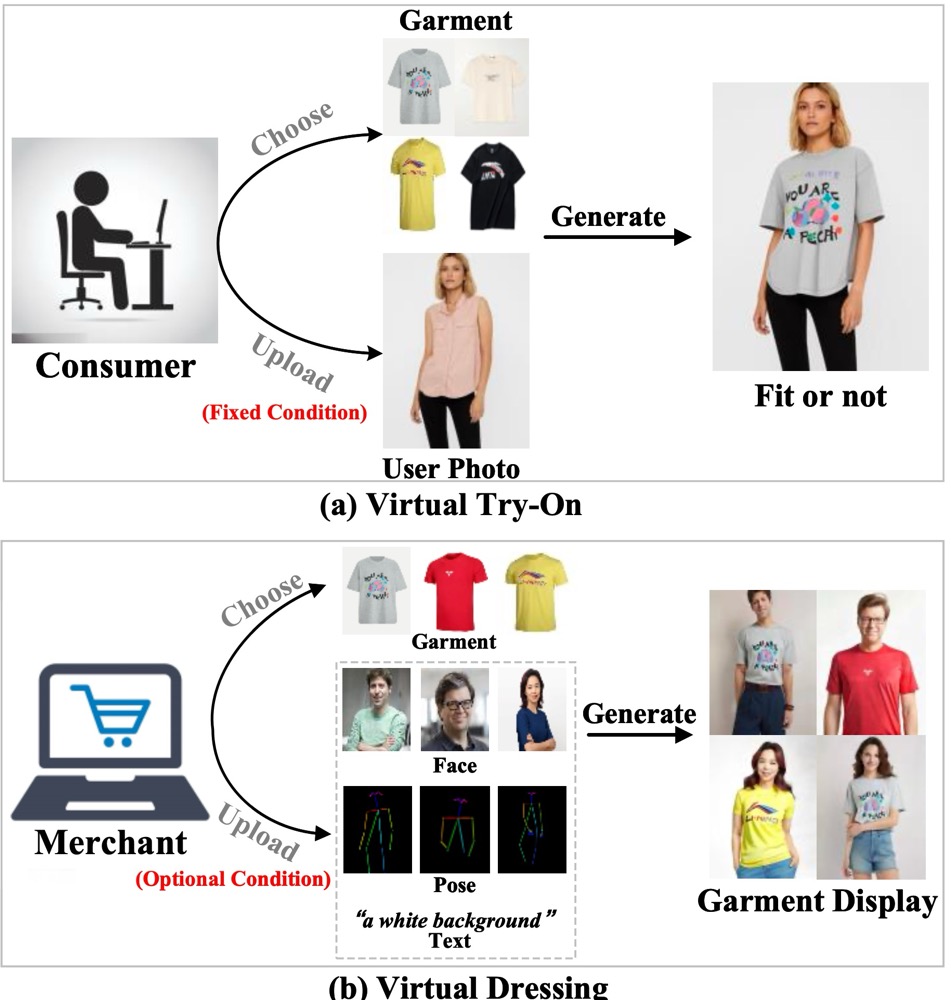
Latest advances have achieved realistic virtual try-on (VTON) through localized garment inpainting using latent diffusion models, significantly enhancing consumers' online shopping experience. However, existing VTON technologies neglect the need for merchants to showcase garments comprehensively, including flexible control over garments, optional faces, poses, and scenes. To address this issue, we define a virtual dressing (VD) task focused on generating freely editable human images with fixed garments and optional conditions. Meanwhile, we design a comprehensive affinity metric index (CAMI) to evaluate the consistency between generated images and reference garments. Then, we propose IMAGDressing-v1, which incorporates a garment UNet that captures semantic features from CLIP and texture features from VAE. We present a hybrid attention module, including a frozen self-attention and a trainable cross-attention, to integrate garment features from the garment UNet into a frozen denoising UNet, ensuring users can control different scenes through text. IMAGDressing-v1 can be combined with other extension plugins, such as ControlNet and IP-Adapter, to enhance the diversity and controllability of generated images. Furthermore, to address the lack of data, we release the interactive garment pairing (IGPair) dataset, containing over 300,000 pairs of clothing and dressed images, and establish a standard pipeline for data assembly. Extensive experiments demonstrate that our IMAGDressing-v1 achieves state-of-the-art human image synthesis performance under various controlled conditions. The code and model will be available at https://github.com/muzishen/IMAGDressing.
Virtual try-on (VTON) vs virtual dressing (VD)
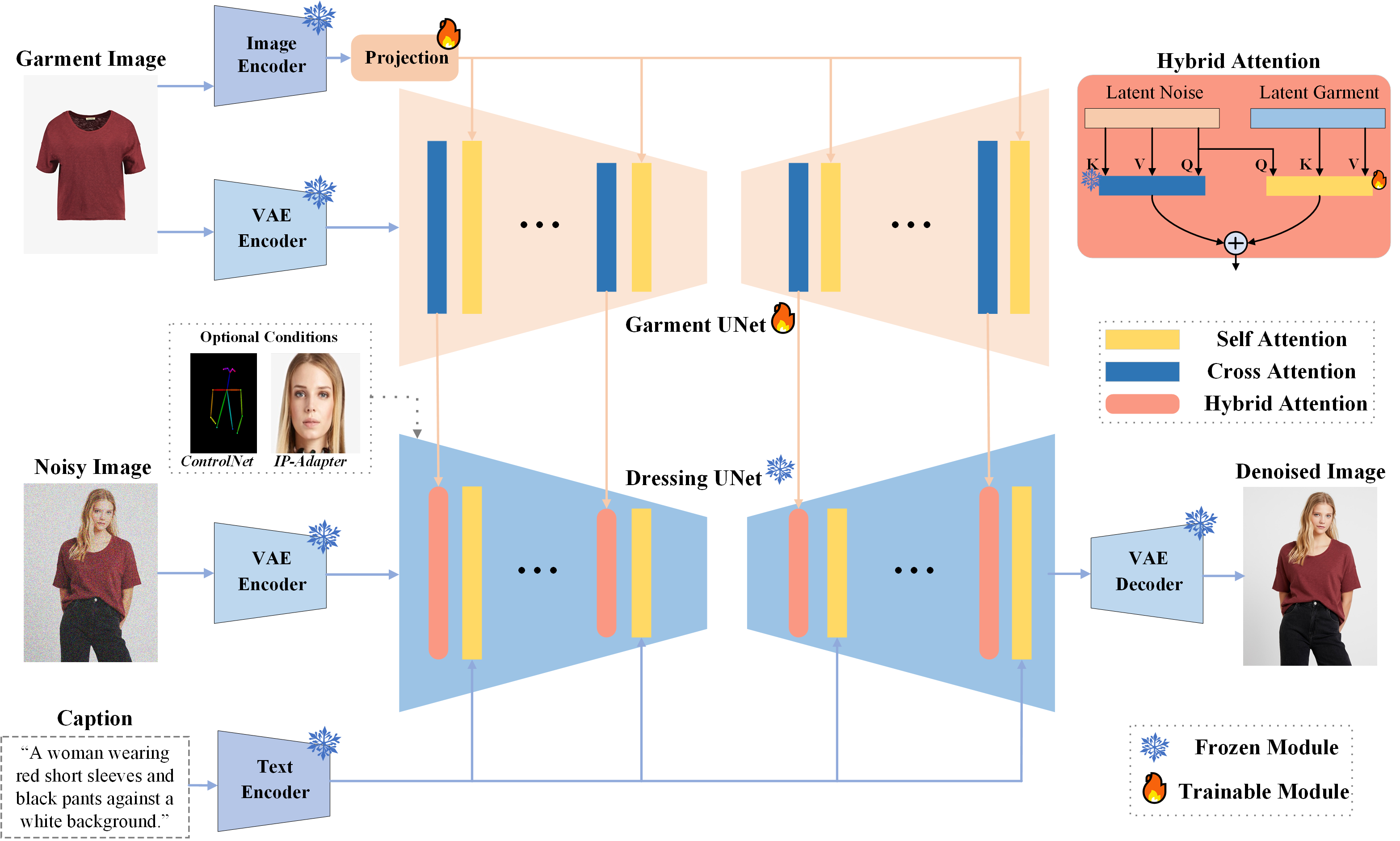
Method
- Simple Architecture: IMAGDressing-v1 produces lifelike garments and enables easy user-driven scene editing.
- New Task: Definition of virtual dressing (VD) Task and design a comprehensive affinity metric index (CAMI) metric
- Flexible Plugin Compatibility: IMAGDressing-v1 modestly integrates with extension plugins such as IP-Adapter, ControlNet, T2I-Adapter, and AnimateDiff.
- Rapid Customization: Enables rapid customization in seconds without the need for additional LoRA training.
- IGPair Dataset: Release a new interactive garment pairing (IGPair) dataset
Compared with MagicClothing

Combined with IP-Adapter
